알렉스 쉬 님의 "가상 면접 사례로 배우는 대규모 시스템 설계 기초" 책을 정리한 포스팅 입니다.
1. 단일 서버
가장 단순한 구조
- 서버 한 대에 모두 탑재
- → 웹 서버, 애플리케이션 서버, 데이터베이스, 캐시
요청 처리 흐름
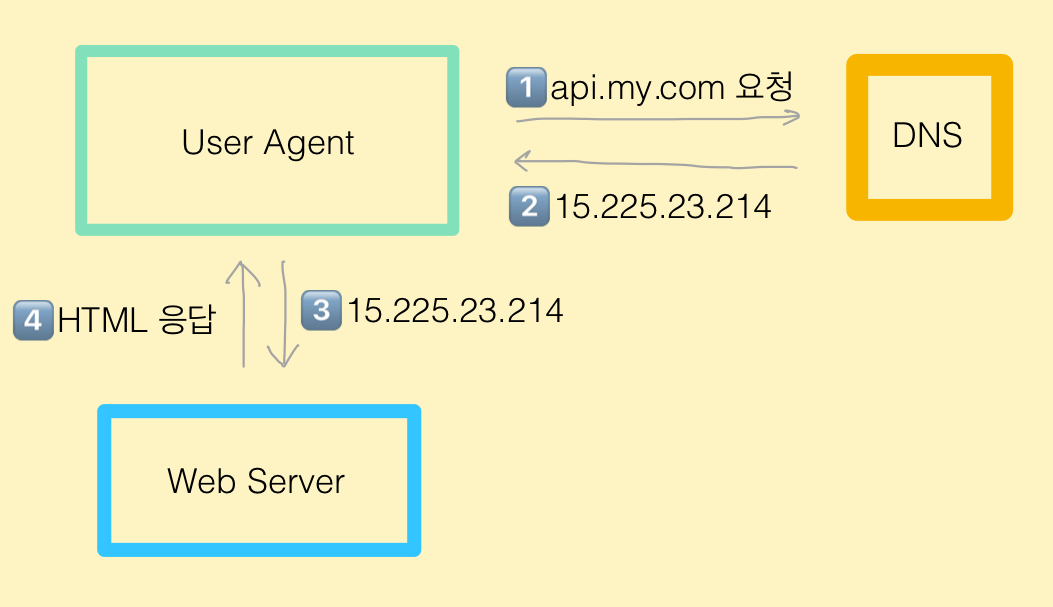
- 접속 시도
- 사용자는 도메인 이름으로 사이트 접속.
- DNS를 통해 도메인을 IP 주소로 변환 (컴퓨터는 도메인 이름을 인식하지 못함)
- HTTP 요청 전송
- 변환된 IP 주소로 HTTP 요청 전송
- 서버 응답
- 서버는 HTML 또는 JSON 형태로 응답함.
2. 데이터베이스
서버 확장의 필요성

- 사용자 수가 늘어나면서 서버 한대로는 감당이 불가해짐
- 서버의 역할을 분리하여 독립적으로 확장
- 애플리케이션 서버: 트래픽 처리
- 데이터베이스 서버: 데이터 관리
데이터베이스 종류
| 항목 | 관계형 데이터베이스 (RDBMS) | 비관계형 데이터베이스 (NoSQL) |
| 대표 시스템 | MySQL, Oracle DB, PostgreSQL |
CouchDB, Neo4j, Cassandra, HBase, Amazon DynamoDB
|
| 데이터 구조 | 테이블(행, 열) 기반 |
Key-Value, 문서형(JSON, XML), 그래프, 칼럼 저장소 등
|
| 사용 언어 | SQL | 시스템별로 다름 (보통 쿼리 언어나 API 제공) |
| 조인 지원 여부 | 조인 연산 가능 | 일반적으로 조인 사용하지 않음 |
| 스키마 구조 | 고정 스키마 | 유연한 스키마 (스키마리스 구조 가능) |
| 적합한 데이터 | 정형 데이터 (Structured) | 비정형 데이터 (Unstructured), 반정형 데이터 |
| 역사 및 안정성 | 40년 이상 검증, 많은 개발자가 익숙 | 상대적으로 신기술, 특정 목적에 최적화 |
NoSQL을 선택하는 경우
| 상황/요구 조건 | NoSQL을 사용하는 이유 |
| 🔸 Low Latency |
- 수평 확장 구조: 부하 분산 가능
- 조인을 하지 않음 - 메모리 기반 처리 (ex. Redis) |
| 🔸 문서형 데이터 저장 필요 |
- JSON, YAML, XML 등을 그대로 저장 가능
- 직렬화/역직렬화가 용이한 문서형 구조 지원 |
| 🔸 매우 많은 양의 데이터 저장 |
- 수평 확장 구조: 데이터 저장소 분산 가능
- 쓰기 성능 최적화 (비동기 쓰기, 로그 기반 저장, eventually consistency 등) |
3. 수직적 규모 확장 vs 수평적 규모 확장
| 항목 | 수직적 확장 (Scale-Up) |
수평적 확장 (Scale-Out)
|
| 개념 | 기존 서버의 하드웨어 성능을 업그레이드 | 여러 대의 서버를 추가하여 동시에 처리 |
| 장점 | - 구조 단순 - 구성 변경 없이 빠르게 성능 향상 - 소규모 시스템에 적합 |
- 부하 분산 - 확장성 - 고가용성 (다른 서버로 자동 전환) |
| 단점 | - 확장 한계 존재 - 단일 장애 시 전체 다운 - 다중화 어려움 |
- 시스템 구성 복잡
- 고려 사항 많음 (세션 공유, 동기화 등) |
| 적합한 상황 | 소규모 서비스 초기 개발 단계 |
대규모 트래픽
고가용성/무중단 요구되는 서비스 |
| 대표 도입 요소 | 하드웨어 업그레이드 | 로드밸런서, 오토스케일링, 클러스터 구성 등 |
로드밸런서
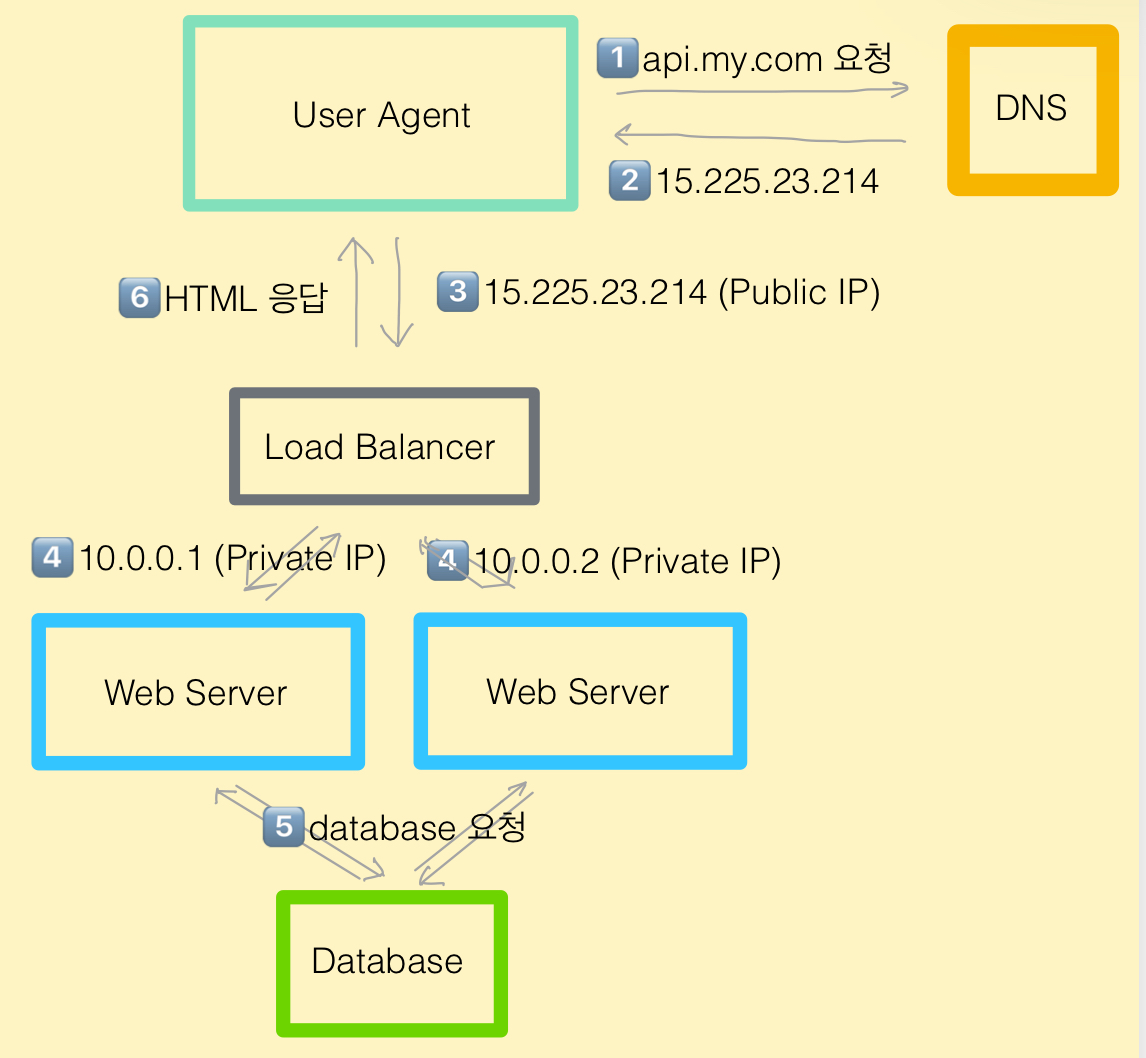
- 서버 계층의 확장을 담당하는 중간 관리자
- 부하 분산 및 고가용성 담당
동작 원리
- 사용자는 로드밸런서의 Public IP로 접속
- 로드밸런서는 요청을 내부 서버들의 Private IP로 전달
- 보안상 내부 서버로 직접 요청 불가
- 서버들은 부하 분산 집합에 포함되어 있음
데이터베이스 복제
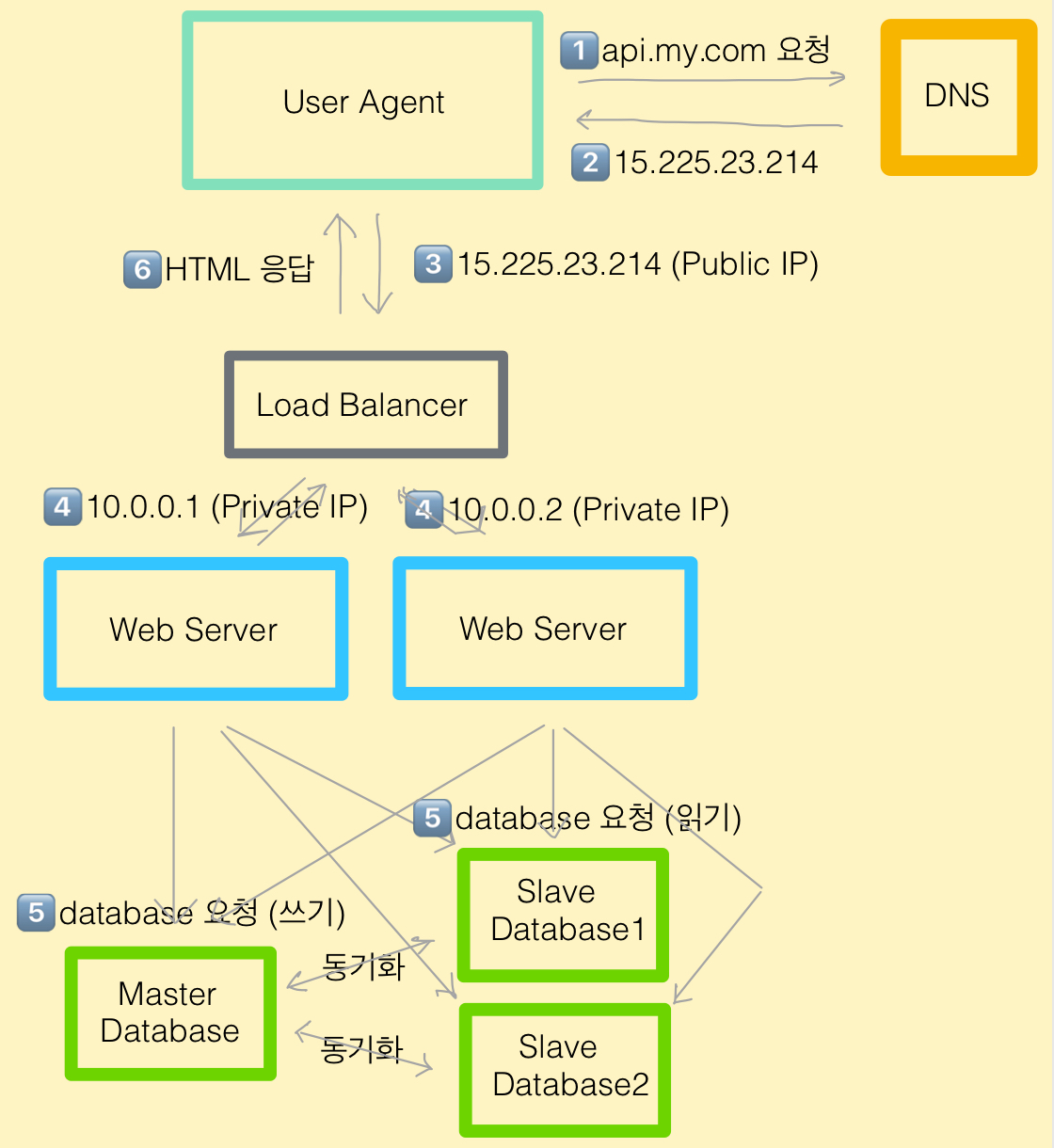
모델 (Master - Slave)
| 역할 | 역할 | 기능 | 갯수 | 동기화 |
| Master DB |
중심 데이터베이스
|
쓰기 연산 전용
|
1대
|
없음 (원본 소스)
|
| Slave DB |
읽기 전용 복제본
|
읽기 연산 전용
|
여러대
|
마스터로부터 실시간 복제
|
효과
| 항목 | 설명 |
| 부하 분산 |
- 읽기 요청을 여러 Slave DB에 분산
→ 성능 향상 (대부분의 애플리케이션은 읽기 요청이 많음) |
| 고가용성 |
- Master DB 장애 발생 시, Slave DB를 승격(promote)하여 서비스 지속
|
4. 캐시
- 자주 조회되거나 계산 비용이 큰 데이터를 미리 저장하여 빠르게 꺼내 쓰기위한 메모리 저장소
캐시 계층
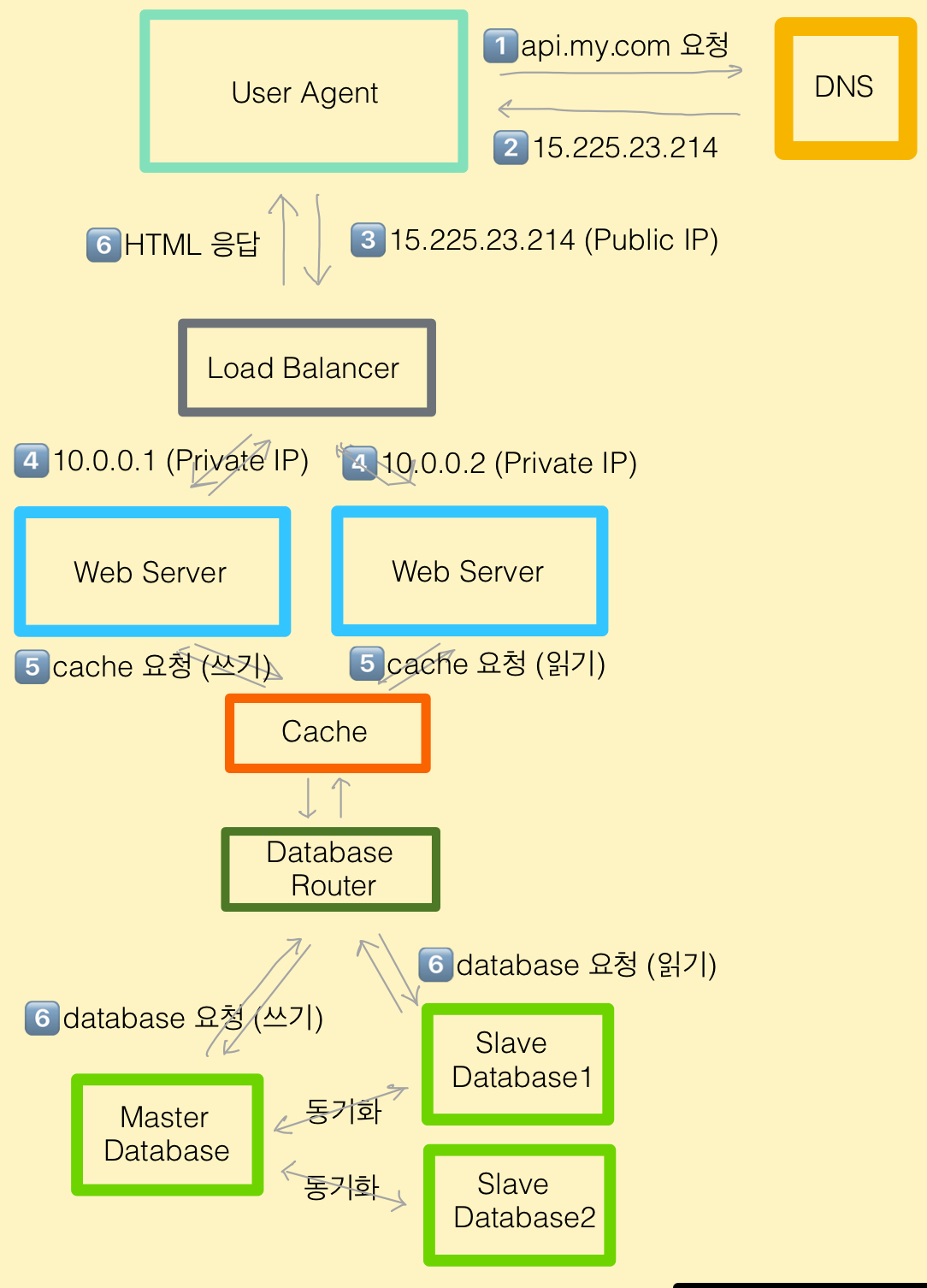
- 웹 서버와 데이터베이스 사이에 위치한 중간 계층
- 캐시에 먼저 있는지 확인하고, 없으면 DB에서 가져옴
- 데이터베이스 조회 횟수를 줄임으로써 성능이 향상됨
- 자주 바뀌지 않는 정보일수록 성능 향샹이 큼
캐시 전략
| 전략 이름 | 설명 |
| Read-through |
서버가 먼저 캐시 확인 → 없으면 DB에서 가져오고 캐시에 저장
|
| Write-through | 데이터를 DB에 쓰면 동시에 캐시에 반영 |
| Write-behind/Back |
DB에는 나중에 비동기로 쓰고, 캐시에 먼저 저장
|
| Cache-aside (Lazy) |
애플리케이션이 직접 캐시 관리 (일반적인 방식)
|
유의 사항
| 항목 | 설명 | 주의사항 / 중요 내용 |
| 캐시가 바람직한 상황 | 데이터 갱신은 드물고, 읽기는 자주 발생하는 경우 |
자주 바뀌는 데이터를 캐시에 두면 문제 발생
→ 불일치 → 오래된 정보 |
| 캐시 저장 대상 | 휘발성 메모리 기반 |
캐시 서버 재시작 시 캐시 데이터는 모두 사라짐
→ 중요한 영속 데이터는 DB 등에 따로 저장해야 함 |
| 만료 정책 | 데이터를 언제까지 캐시에 둘지 명확하게 설정해야 함 |
- 짧을 경우: 캐시 미스 잦아지고 DB 부하 증가
- 길 경우: 원본과 불일치 가능성 증가 |
| 일관성 | 캐시와 DB 간 데이터가 다르면 문제 발생 | 분산 환경일 경우 일관성 유지 어려움 (에러 발생 후처리) → 추천: cache invalidation (가장 간단함) |
| 장애 대응 | 캐시 서버 1대만 있으면 단일 장애 지점(SPOF) 됨 |
장애 시 전체 서비스 영향
→ 여러 지역에 캐시 서버 분산 필요 |
| 캐시 메모리 용량 | 너무 작으면 캐시가 자주 밀려(eviction) 성능 저하 | 보통은 여유 있게 설정 → 추천: overprovisioning |
| 데이터 방출 정책 | 캐시가 가득 찼을 때 어떤 데이터를 버릴지 결정 |
- LRU (최근에 가장 오래 안 쓴 데이터 제거)
- LFU (사용 빈도 낮은 데이터 제거) - FIFO (먼저 들어온 데이터부터 제거) → 데이터 특성과 사용 패턴에 따라 선택 필요 |
5. CDN
- 지리적으로 분산된 서버들로 구성된 네트워크
- 정적 콘텐츠를 사용자에게 빠르게 제공
- → 서버 부하를 줄임
예) 서비스별 정적 리소스
더보기
- 모든 웹 애플리케이션: HTML / CSS / JS / font / image
- 넷플릭스: video
- 쇼핑몰: 상품 썸네일
- 언론사: 기사 이미지
동작 원리

- 사용자: 웹사이트 방문 (정적 리소스 요청)
- (사용자의 위치에서 가장 가까운) CDN 서버: 정적 리소스 응답
- 정적 리소스 캐싱 ✅: 바로 응답
- 정적 리소스 캐싱 ❌: origin 서버로부터 가져온 후 캐싱 및 응답 (리소스에 유효시간 지정)
유의 사항
| 항목 | 설명 | |
| 비용 | 데이터 전송량(트래픽)에 따라 과금됨 | |
| TTL 설정 | 콘텐츠 특성에 맞는 TTL 전략이 필요 |
시의성이 중요한 콘텐츠 (예: 뉴스 헤드라인, 이벤트 배너 등)
- 너무 긴 TTL을 주면 신선도 저하 - 너무 짧으면 원본 서버에 부하 발생 |
| 장애 대응 |
CDN 서버에 문제가 생겼을 때, 클라이언트가 자동으로 원본 서버에 fallback할 수 있도록 구성 필요.
|
클라이언트, 로드 밸런서, 서비스 워커 등에 백업 로직 필요
|
| 콘텐츠 Invalidation |
콘텐츠 즉시 갱신이 필요할 때 무효화할 수 있음
|
① CDN 제공 API로 수동 무효화
② 버전 쿼리 파라미터 사용 (예: logo.png?v=2) |
| 정적 콘텐츠 전용화 |
정적 콘텐츠는 CDN에서만 제공하는 구조가 일반적
|
성능 최적화 및 서버 부하 분산에 효과적.
|
| 백엔드 부하 감소 |
CDN이 콘텐츠를 캐시함으로써 백엔드 서버나 DB에 대한 요청을 줄일 수 있음
|
이미지, 리소스 관련 트래픽이 많은 경우 효과 큼.
|
6. Stateless Web
- 웹 계층을 수평적으로 확장하기 위해서는 웹 계층에서 상태 정보를 제거해야 함 (로드밸런싱 제약 없애기)
Web Server Architecture
| 항목 | Stateful Architecture | Stateless Architecture |
| 상태 저장 위치 | 서버 내부 (메모리 등) | 외부 공유 저장소 (Redis, DB 등) |
| 서버 간 상태 공유 | 불가능 (서버 간 독립적) | 가능 (공유 저장소에서 조회) |
| 확장성 | 낮음 (로드밸런서 제약, 서버 추가 어려움) | 높음 (Auto Scaling 용이) |
| 서버 제거 | 어려움 (세션 유실 우려) | 자유로움 (상태가 없음) |
| 장애 대응 | 특정 서버 장애 시 세션 유실 가능 | 다른 서버로 대체 가능 (Fault Tolerance) |
| 글로벌 분산(Multi-region) | 어렵고 제한적 | 쉽게 가능 (동일한 구조 유지) |
| 운영 편의성 | 배포/재시작 시 세션 문제 발생 | 유지보수, 롤링 업데이트에 유리 |
| 로드밸런서 라우팅 | Sticky Session 필요 | 자유로움 |
7. 데이터 센터

- 백엔드 전체 계층이 통합된 물리적 인프라 단위
- multi-region에 각 데이터 센터를 두어 글로벌 트래픽을 감당함
기능
- 지리적 라우팅: 사용자 요청을 지리적 위치에 따라 가장 가까운 데이터 센터로 연결
장점
- 글로벌 커버리지: 전 세계 트래픽을 효율적으로 처리할 수 있음
- 성능 최적화: 사용자는 가장 빠르게 응답을 받음
- 장애 대응: 특정 지역에 대한 장애에 대해 failover할 수 있음
기술적 과제 및 해결 전략
| 과제 | 설명 | 해결 전략 |
| Geo Routing | - 사용자의 요청을 가장 가까운 데이터 센터로 라우팅 - 장애 발생 시 다른 센터로 자동 우회 필요 |
- GeoDNS
- Anycast - 글로벌 로드 밸런서 (AWS Route53, Cloudflare Load Balancing) |
| Data Synchronization | 각 데이터 센터가 별도 DB를 쓰면, failover 시 필요한 데이터가 없을 수 있음 | Cross-region DB replication - Primary-Replica - multi-master replication - masterless replication |
| 테스트와 배포 | 데이터 센터가 여러 곳이면, 기능과 배포가 일관되게 동작해야 함 |
- 멀티 리전 테스트 자동화
- CI/CD 파이프라인을 글로벌하게 확장 - 모든 센터에 동일한 이미지/코드 배포 |
| 컴포넌트 분리 / 독립적 확장 | - 서비스 전체를 복제하면 비용/복잡도 증가 - 특정 컴포넌트만 더 늘리고 싶을 수 있음 |
- 마이크로서비스 아키텍처 도입 - 컴포넌트별로 독립 확장 가능하도록 분리 |
| Message Queue | 시스템 간 동기 통신은 지연/장애 확산 위험이 큼 | - 비동기 메시징으로 decoupling - 서비스 간 통신을 느슨하게 연결 - 예: Kafka, RabbitMQ, SQS 등 |
표) Cross-region DB replication
더보기
| 항목 | Primary-Replica | Multi-Master Replication | Masterless Replication |
| 구조 | Primary + 여러 Read Replica | 각 리전에 독립적인 Master 구성 | 모든 노드가 동등 (P2P 구조) |
| 읽기 위치 | 모든 리전 (로컬 Read 가능) | 모든 리전 | 모든 노드 가능 |
| 쓰기 위치 | 하나의 Primary 리전에서만 가능 | 모든 리전에서 쓰기 가능 | 모든 노드에서 쓰기 가능 |
| 복제 방향 | 단방향 (Primary → Replica) | 양방향 | 양방향 (peer-to-peer) |
| 대표 기술 | - AWS Aurora Global DB - MySQL Read Replica - Cloud Spanner |
- MySQL InnoDB Cluster - PostgreSQL BDR - Couchbase XDCR |
- Apache Cassandra
- DynamoDB Global Tables - ScyllaDB |
| 장점 | - 읽기 지연 낮음 - 충돌 없음 - 일관성 강함 |
- 고가용성 - 리전별 독립 운영 |
- 고가용성 - 뛰어난 확장성 - 노드 장애 자동 대체 |
| 단점 | - 쓰기 리전 지연 가능 - Primary 장애 시 전환 필요 |
- 충돌 가능성 - conflict 해결 필요 |
- Eventual consistency - 복잡한 consistency 설정 |
| 일관성 수준 | 강한 일관성 | 중간 (충돌 관리 필요) | 약한 일관성 (설정 가능) |
| 확장성 | 중간 | 중간~높음 | 매우 높음 |
| 장애 대응 | 수동/자동 전환 필요 | 자동 또는 수동 전환 | 자동 전환 가능 (노드 단위) |
8. 메시지 큐

- 웹 서비스간 비동기 통신을 가능하게 해주는 시스템
구성 요소
| 구성 요소 | 설명 | example |
| Producer / Publisher |
메시지를 생성하여 큐에 전송하는 주체
|
API 서버, 백엔드
|
| Queue (Broker) |
메시지를 일시적으로 저장해두는 중간 버퍼 역할
|
Kafka, RabbitMQ
|
| Consumer / Subscriber |
큐에서 메시지를 가져와 처리하는 주체
|
이미지 처리 워커
|
장점
| 항목 | 설명 |
| Async Communication |
생산자와 소비자가 동시에 동작하지 않아도 메시지 처리 가능
|
| Durability |
한 쪽이 다운되어도 메시지를 안전하게 큐에 보관 가능
|
| 확장성 |
큐 길이에 따라 워커(소비자) 수를 독립적으로 조절 가능
|
| 버퍼링 |
트래픽 급증 시 처리 지연 없이 메시지를 버퍼링
|
| Loose Coupling |
API 호출 없이도 메시지로 연결
→ 독립 배포와 유지보수 용이 |
9. 로그, 매트릭 그리고 자동화
- 운영 인프라 핵심 요소
- 초기에는 없어도 되지만, 시스템이 성장하고 복잡해질수록 반드시 도입해야 함
요소

| 항목 | 설명 | 목적 |
| Logging | - 기록 (에러/이벤트/사용자 활동) - 수집 (로컬 파일 또는 중앙 로그 수집기로 전송) |
- 문제 원인 추적 - 보안 감사 - 사용자 행위 분석 |
| Metrics | - 실시간 수치 데이터 수집 - 시스템, DB, 캐시, 비즈니스 지표 등 |
- 성능 모니터링
- 트래픽 추이 분석 - 경고 조건 탐지 |
| Automation | - 빌드, 테스트, 배포, 린트 - CI/CD 파이프라인 구축 |
- 반복 작업 제거 - 빠른 피드백 - 릴리즈 안정화 |
10. 데이터베이스의 규모 확장
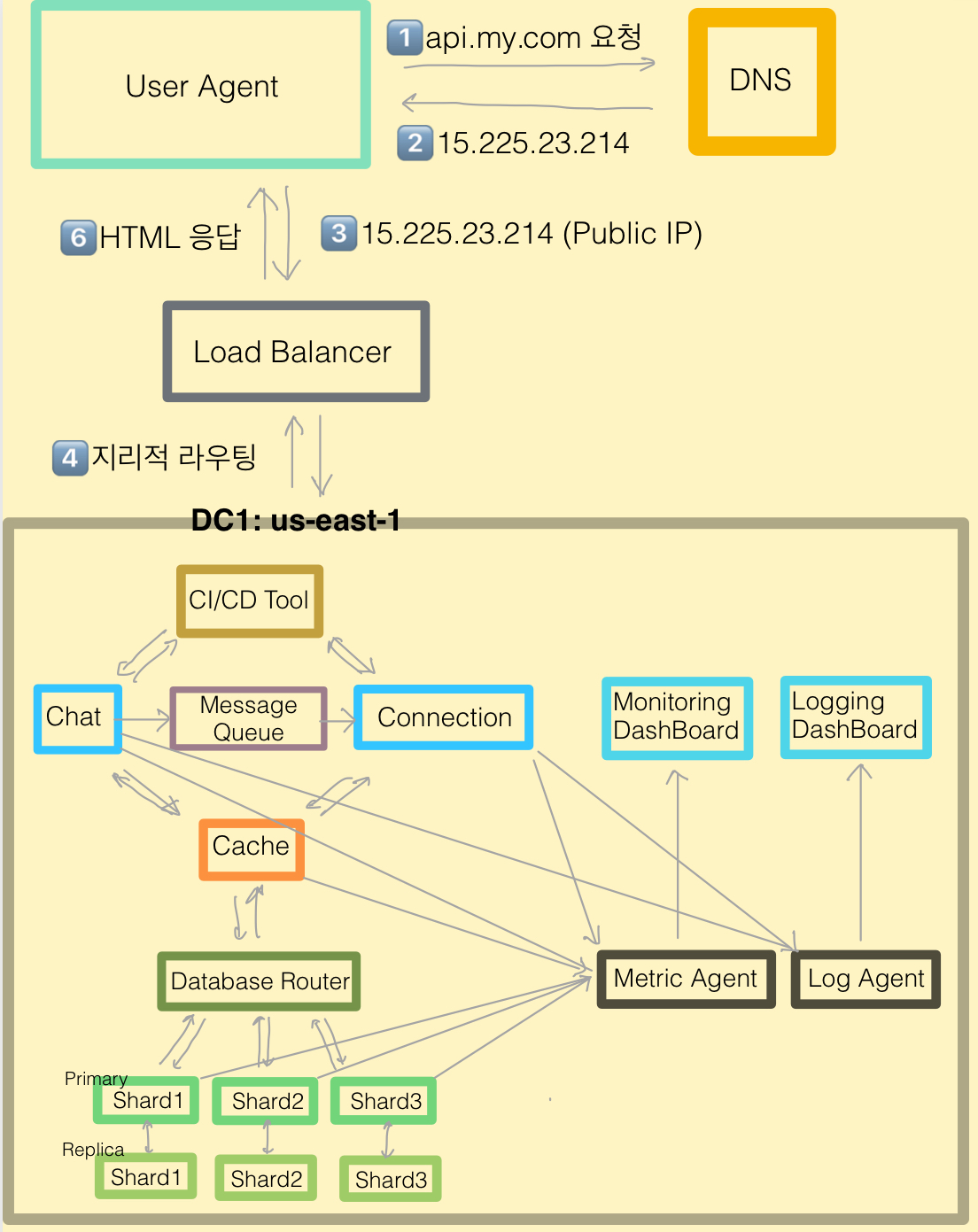
- 저장할 데이터가 많아지면 데이터베이스 부하도 증가함
- 이럴 경우 데이터베이스를 증설해야 함
전략
| 항목 | 수직적 확장 (Vertical Scaling) |
수평적 확장 (Horizontal Scaling / Sharding)
|
| 📌 개념 | 고성능 하드웨어로 기존 DB 서버 업그레이드 | DB를 여러 개 샤드로 나누어 분산 처리 |
| 📌 구조 변경 | 거의 없음 | 필요함 (샤드 구성 및 라우팅 설계) |
| 📌 개발 복잡도 | 낮음 (기존 앱 로직 그대로) | 높음 (샤드 키 설계, 데이터 라우팅 필요) |
| 📌 예시 | AWS RDS 고사양 인스턴스 사용 | userId % 4로 4개 샤드에 분산 저장 |
| ✅ 장점 | - 단순한 구조 유지 - 빠른 적용 가능 |
- 장애 격리 - 트래픽 분산 - 확장성 |
| ❌ 단점 | - 하드웨어 한계 - SPOF 위험 - 비용 급증 |
- 샤드 키 설계 어려움
- Resharding 필요 - 핫스팟 발생 위험 - 조인 어렵고 비정규화 필요 |
주요 문제 및 해결 전략
| 문제 유형 | 설명 | 대표 해결 방법 |
| Resharding | 일부 샤드만 빠르게 가득 차거나 전체 데이터 양이 증가할 때 |
- 샤드 키 변경
- Consistent Hashing 적용 - 수평 확장 자동화 |
| Hotspot | 특정 키에 요청이 몰려 특정 샤드에 부하 집중 (유명인, 인기 콘텐츠 등) |
- 해당 키를 독립 샤드로 분리
- 더 작은 단위로 세분화 샤딩 |
| 조인 / 정규화 문제 | 샤드 간 데이터가 분산되어 있어 조인 쿼리 어려움 |
- 비정규화된 구조로 테이블 설계
- 쿼리가 단일 샤드에서 끝나도록 설계 |
'Code' 카테고리의 다른 글
| [가상 면접 사례로 배우는 대규모 시스템 설계 기초] 6. 키-값 저장소 설계 (3) | 2025.08.02 |
|---|---|
| [가상 면접 사례로 배우는 대규모 시스템 설계 기초] 2. 개략적인 규모 추정 (5) | 2025.08.01 |
| [도메인 주도 개발 시작하기: DDD 핵심 개념 정리부터 구현까지] 10. 이벤트 (0) | 2025.06.20 |
| [도메인 주도 개발 시작하기: DDD 핵심 개념 정리부터 구현까지] 9. 도메인 모델과 바운디드 컨텍스트 (0) | 2025.06.20 |
| [도메인 주도 개발 시작하기: DDD 핵심 개념 정리부터 구현까지] 8. 애그리거트 트랜잭션 관리 (0) | 2025.06.19 |