알렉스 쉬 님의 "가상 면접 사례로 배우는 대규모 시스템 설계 기초" 책을 정리한 포스팅 입니다.
1. 문제 이해
요구 조건
| 항목 | 요구 사항 내용 |
| 값 크기 제한 | 1쌍(Key-Value) ≤ 10KB |
| High Availability |
장애 상황에서도 빠르게 응답해야 함
|
| Low Latency |
빠른 응답 속도 보장 필요
|
| Scalability |
트래픽 변화에 따라 서버 자동 증설/축소 가능
|
| Consistency 조정 가능 |
사용자가 요구하는 대로 일관성 수준 선택 가능
|
2. 분산 키-값 저장소
- 키-값 쌍을 여러 서버에 분산시킴
CAP 정리
- 분산 시스템에서는 Consistency - Availability - Patition Tolerance 모두를 만족하지 못함
| 개념 | 설명 |
| Consistency (일관성) |
모든 노드에서 항상 같은 데이터를 반환해야 함
|
| Availability (가용성) |
모든 요청에 대해 응답을 반드시 반환해야 함 (성공/실패와 관계없이)
|
| Partition Tolerance (파티션 감내성) |
네트워크가 분리(partition)되더라도 시스템이 동작 가능해야 함
|
시스템 유형
| 유형 | 포기한 특성 | 설명 |
| CP 시스템 | ❌ Availability |
네트워크 문제가 발생하면 응답을 거부함으로써 일관성을 보장
|
| AP 시스템 | ❌ Consistency |
네트워크 문제가 생겨도 응답은 하지만 데이터는 잠시 불일치 가능
|
| CA 시스템 | ❌ Partition Tolerance |
현실에서는 존재 불가능 (네트워크 장애는 언젠가 반드시 발생하므로)
|
예시) 시스템 유형
더보기
| 시스템 | CAP 특성 (가장 유사한 분류) | 설명 |
| HBase | CP |
Strong consistency 우선
응답 속도보다 정확함 우선 |
| Redis Sentinel | CP (단일 마스터 구조) | 네트워크 분리되면 가용성보다 일관성을 우선. |
| ZooKeeper | CP |
분산 락/구성 관리용.
항상 정확한 상태 보장 필요. |
| Cassandra | AP |
항상 응답은 함
단, 잠깐 데이터 불일치 허용 가능. |
| Amazon Dynamo | AP |
네트워크 분리되어도 고가용성 유지.
일관성은 tunable. |
3. 시스템 컴포넌트
데이터 파티션
- key-value 쌍의 데이터를 여러 서버에 나누어 저장하는 방식
- ✅ 균등 분산: 모든 서버에 데이터가 고르게 분산되어야 함
- ✅ 데이터 이동 최소화: 서버 추가/삭제 시 최소한의 데이터만 이동해야 함
consistent hasing

- 분산 시스템에서 데이터를 여러 서버에 안정적으로 분배하는 핵심 알고리즘
- ✅ 서버와 키를 같은 해시 공간에 매핑
- ✅ 키는 시계 방향으로 가장 먼저 만나는 서버에 저장됨
- ➡️ auto scaling: 서버 추가/삭제 시, 해당 링에 자동으로 키 배치
| 항목 | 설명 | 중요한 점 |
| 재분배 최소화 | 서버 추가 삭제 시, 해당 해시 범위만 재배치 | 추가 되는 서버의 범위 외 다른 범위는 영향 안 받음 |
| 서버 이질성 대응 | 가상 노드 할당 수 조절을 통해 서버별 차이 반영 | 가상 노드: 하나의 실제 서버를 해시 링에 여러 위치에 중복 배치 ➡️ 성능: 더 많은 가상 노드를 두어 배치 확률을 높임 ➡️ 재분배 최소화: 각 할당 노드 수를 늘려 간격의 차이를 줄임 |
데이터 다중화(replication)
- 데이터를 여러 서버에 복제해서 저장하면 가용성 / 안정성이 증가함
consistent hashing 사용
- 링 위에 키를 배치하고, 시계방향으로 링을 순회하면서 만나는 첫 N개 서버에 데이터 사본을 보관함
가상노드 사용 시 주의점
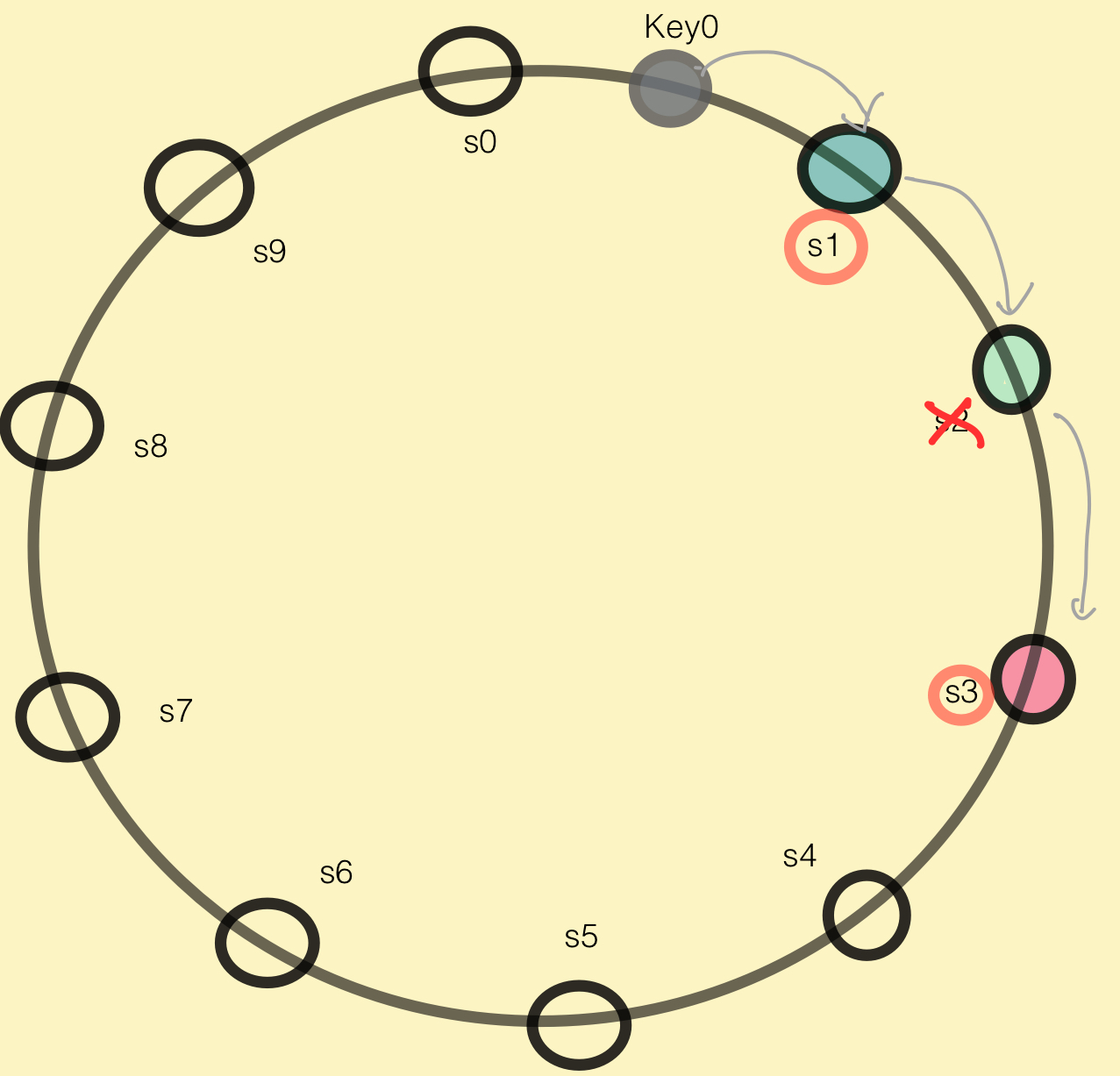
- 선택된 N개의 서버 모두 같은 물리 서버에 속해버릴 수 있음
- → 물리적으로 서로 다른 N개의 서버가 뽑힐때까지 시계방향 순회
일관성(consistency)
- 여러 노드에 다중화된 데이터는 적절히 동기화 되어야 함
- 읽기/쓰기 연산 모두에 일관성을 보장할 수 있음
일관성 모델
- 분산 저장소에서 읽기/쓰기 연산 시 데이터가 얼마나 일관되게 보장되는지를 정의하는 규칙
| 항목 | Strong Consistency | Weak Consistency | Eventual Consistency |
| 정의 | 항상 가장 최신 데이터를 반환함 | 최신 데이터 반환 보장 없음 | 시간이 지나면 모든 노드가 일관 상태에 도달 |
| 읽기 결과 | 가장 최근 쓰기 결과 | 최신이 아닐 수 있음 | 일시적으로 불일치할 수 있음 |
| 가용성 | 낮음 (쓰기 전파 대기) | 높음 | 매우 높음 |
| 충돌 가능성 | 거의 없음 | 있음 | 있음 (클라이언트에서 버전 비교 필요) |
| 실현 방식 | 정족수 합의 프로토콜 (W+R > N) | 정족수 합의 프로토콜 (W+R <= N) | |
| 적용 예시 | 은행 시스템, 거래 DB | 캐시, 임시 결과 | SNS, 로그 수집, 메시징 큐 |
| 대표 제품 | MongoDB (strict) | Redis (복제 지연, AOF 비활성화) | Dynamo, Cassandra |
Eventual Consistency) 충돌 해결
더보기
- 동시에 서로 다른 클라이언트가 같은 키의 값을 수정하면 백그라운드 동기화 중 충돌이 생길 수 있음
- 시스템은 충돌된 복수 버전을 클라이언트에게 병합을 위임함
- 클라이언트는 버전 정보를 비교해서 적합한 값으로 병합함
정족수 합의 프로토콜
- 충분한 수의 노드로부터 응답을 받으면 성공으로 간주함
- 중재자에 의해 성공 응답을 받을 경우 성공으로 인정
| 용어 | 의미 |
| N | 데이터 사본(replica)의 개수 |
| W |
쓰기(Write) 연산이 성공했다고 인정받기 위해 필요한 최소 응답 수
|
| R |
읽기(Read) 연산이 성공했다고 인정받기 위해 필요한 최소 응답 수
|
| W | R | W+R | 일관성 수준 | 설명 | 사용 예 |
| 1 | 1 | 2 | ❌ 약한 일관성 |
빠르지만 최신 데이터 아닐 수 있음
|
모니터링 |
| 1 | 3 | 4 | ✅ 강한 일관성 |
쓰기 위주: 읽기 느림 / 쓰기 빠름
|
로그 저장
|
| 2 | 2 | 4 | ✅ 강한 일관성 | 균형 잡힌 구성 | 일반적인 시스템 |
| 3 | 1 | 4 | ✅ 강한 일관성 |
읽기 위주: 읽기 빠름 / 쓰기 느림
|
캐시
|
일관성 불일치 해소(inconsistency resolution)
- 충돌을 감지하고 해결하려면 버전 추적과 비교 필요 (단순한 timestamp만으로는 부족)
벡터 시계
- 각 데이터에 대해 [서버ID, 버전] 정보
- 데이터가 쓰일 때, 해당 서버의 버전 카운터만 증가
- 각 노드별 데이터에 대해 서로 일부는 크고 일부는 작은 경우, 충돌로 간주함 → 병합 필요
벡터 시계) 충돌 발생
더보기
- ✅ A = [(s0,1), (s1,1)], B = [(s0,1), (s1,2)] : s1만 B가 큼 ⇒ 충돌 아님 (A는 B의 선행버전)
- 💥 A = [(s0,1), (s1,2)], B = [(s0,2), (s1,1)] : s0는 A가 크고 s1은 B가 큼 ⇒ 충돌
장애 감지
- 분산 시스템에서 단지 "서버 A가 죽었다"라고 주장하는 것은 신뢰할 수 없음
- 다수의 노드가 동일한 증거를 바탕으로 판단할 때만 실제 장애로 간주함
가십 프로토콜
- 분산형 장애 감지 방법
- 분산된 합의의 결과 장애 노드를 찾아냄
| 항목 | 설명 |
| 확장성 |
전체 노드 수가 많아져도 일부 노드만 전파 → 네트워크 부담 적음
|
| 내결함성 |
중앙 장애 감지 노드 없이도 전체가 분산적으로 감지 가능
|
| 점진적 확산 |
장애 정보가 점점 전체로 퍼지면서 신뢰도도 함께 높아짐
|
가십 프로토콜) 동작 원리
더보기
- 각 노드는 전체 멤버에 대한 멤버십 목록을 유지
- 각 멤버는 [멤버 ID, Heartbeat Counter, Timestamp]로 표현됨
- 자기 자신의 heartbeat만 직접 증가시킴
- 노드들의 상태 동기화
- 특정 노드에게 자기 맵을 전송
- 수신한 노드는 자기보다 높은 heartbeat가 있으면 갱신
- → 각자 자신이 가진 멤버십 목록이 수렴됨
- 장애 노드 찾기
- 일정 시간동안 heartbeat가 증가하지 않은 멤버를 장애로 간주
- → 누가 정말로 응답이 없는지를 다수가 알게됨
장애 처리
- 장애 감지 시, 시스템은 가용성을 보장하기 위해 필요한 조치를 취해야 함
| 항목 | 일시적 장애 처리 | 영구 장애 처리 |
| 처리 기법 | Hinted Handoff | Anti-Entropy Protocol |
| 대상 상황 | 일시적 네트워크 오류 / 서버 일시 불능 | 서버 영구 손실 또는 오랜 시간 쓰기 누락 |
| 동작 방식 | 다른 노드가 임시로 요청 처리 후 복구 시 해당 데이터를 다시 전달 |
사본 간의 데이터 비교로 일관성 깨진 부분 찾아 동기화
|
| 동작 시점 | 장애 노드가 복구될 때 | 주기적으로 또는 복구 시 강제 동기화 필요 |
| 전달 방식 | 저장된 hint를 장애 노드에 넘김 | Merkle Tree를 사용해 비교 → 차이만 동기화 |
| 일관성 회복 | 복구 노드가 위탁받은 데이터 적용 | 사본 비교 후 차이 나는 버킷만 업데이트 |
| 장점 | 빠르게 요청 처리, 네트워크 낭비 없음 | 전체 데이터 재전송 없이 효율적 복구 |
| 단점 | 장시간 장애 시 hint 유실 위험 | Merkle Tree 비교/구성 비용 발생 |
Anti-Entropy Protocol) Merkle Tree
더보기
Root
/ \
Parent1 Parent2
/ \ / \
H(A) H(B) H(C) H(D)- 각 노드가 관리하는 키 공간을 해시 및 이진트리로 구성
- 효율적으로 비교하여 동기화할 수 있게 해줌
쓰기 경로(Cassandra)
- 커밋 로그 기록
- WAL 역할 (장애 시 데이터 유실 방지)
- append 방식이므로 속도 빠름
- 메모리 캐시에 반영
- 데이터를 메모리 상의 구조에 반영 (key-value 형태)
- 메모리 캐시 가득찰 경우, SSTable로 플러시
읽기 경로(read path)
- 메모리 캐시 확인
- 블룸 필터 확인
- SSTable에 Key가 있는지 빠르게 판단할 수 있는 확률적 자료구조
- SSTable 확인
- 블룸 필터로부터 후보 SSTable 좁힘
- 디스크로부터 SSTable 읽기
- 결과 반환
시스템 아키텍처 다이어그램

'Software Engineering' 카테고리의 다른 글
| [가상 면접 사례로 배우는 대규모 시스템 설계 기초] 12. 채팅 시스템 설계 (3) | 2025.08.03 |
|---|---|
| [가상 면접 사례로 배우는 대규모 시스템 설계 기초] 10. 알림 시스템 설계 (3) | 2025.08.02 |
| [가상 면접 사례로 배우는 대규모 시스템 설계 기초] 2. 개략적인 규모 추정 (5) | 2025.08.01 |
| [가상 면접 사례로 배우는 대규모 시스템 설계 기초] 1. 사용자 수에 따른 규모 확장성 (2) | 2025.07.31 |
| [도메인 주도 개발 시작하기: DDD 핵심 개념 정리부터 구현까지] 10. 이벤트 (0) | 2025.06.20 |